Search results
20 results found.
Artificial Intelligence / Reverse Engineering / Internet of Things / Full Stack Developer
20 results found.

我真的是以欣赏的角度看的,挺好看。很有态度,感觉真的像一个传媒公司,镜头,画面,转场,特写都很专业。艺人也是很敬业,很佩服他们. ..
U1S1演员确实没研究,怎么说也是小电影还是需要演技的。但这些演员都是真刀真枪的干。要是能真的请到传媒学院的或者那些圈里的明星估计会更好。– 糊胡涂
我没有要传播色情的意思,只是对于爬取的数据进行分析的时候,总会有些出乎意料的发现。在国内所有的情色内容都是不合法的,但是违法的事情确并没有因此而销声匿迹。通过最近的分析,我发现色情产业这个规模异常的庞大。原来想写一篇简单的分析文章,现在却发现自己分析的不过是冰山一角。现在的色情行业已经不再仅仅局限于提供色情视频的观看,点播下载。现在基于各种直播平台的在线直播,打赏,网红主播,TS CD,甚至有专门的编剧,导演拍摄,并且喊着口号甚至要超越日本,成为世界第一。
大家好,我是麻豆傳媒P先生。 謝謝大家一直對麻豆的支持,我們想打造屬於華人的中文市場,不讓日本一直走在我們前面,我們持續努力前行,打造華人的驕傲! 最近有許多人不斷的盜取麻豆的原創影片,我想這可能是大家還不習慣屬於華人國產影片的出現。感謝所有的同行跟我們一起努力,為每個人的夜晚去打造歡愉,但是盜取麻豆的影片只會讓歡愉更快的消失,讓華人國產停滯不前。 –麻豆传媒


所谓“伪娘”,即通过女装、化妆等手法让外人认为是女性的男性,我们通常可以在各地的漫展上看到相当数量的“伪娘”,这也是二次元文化中的萌属性之一。
而“药娘”则不同,简单来说就是心理性别为女,生理性别为男的跨性别者,他们通常是依靠激素药物改变内分泌,从而让自己身体特征逐渐接近女性。这个群体的人数非常稀少且又特殊,直至去年(2016年?根据参考链接文章编辑时间推测。)才在网络上出现相关讨论,但目前并没有引起社会的广泛关注。

声明:本文中所有数据都是来源于第三方福利网站的数据,本文仅对数据中相关的信息进行解析。本人非常喜欢这些女明星,绝无抹黑之意。
from pyspark.sql.functions import col
import altair as alt
import pandas as pd
from matplotlib import pyplot as plt
%matplotlib inline
csv = spark.read.option("header",True).csv("hdfs://localhost:9000/data2/porn_data_movie.csv")
csv.printSchema()
root |-- id: string (nullable = true) |-- create: string (nullable = true) |-- update: string (nullable = true) |-- name: string (nullable = true) |-- describe: string (nullable = true) |-- source_id: string (nullable = true) |-- publish_time: string (nullable = true) |-- play_count: string (nullable = true) |-- good_count: string (nullable = true) |-- bad_count: string (nullable = true) |-- link_count: string (nullable = true) |-- comment_count: string (nullable = true) |-- designation: string (nullable = true) |-- category_id: string (nullable = true) |-- porn_site_id: string (nullable = true) |-- uploader_id: string (nullable = true) |-- producer: string (nullable = true)
'''
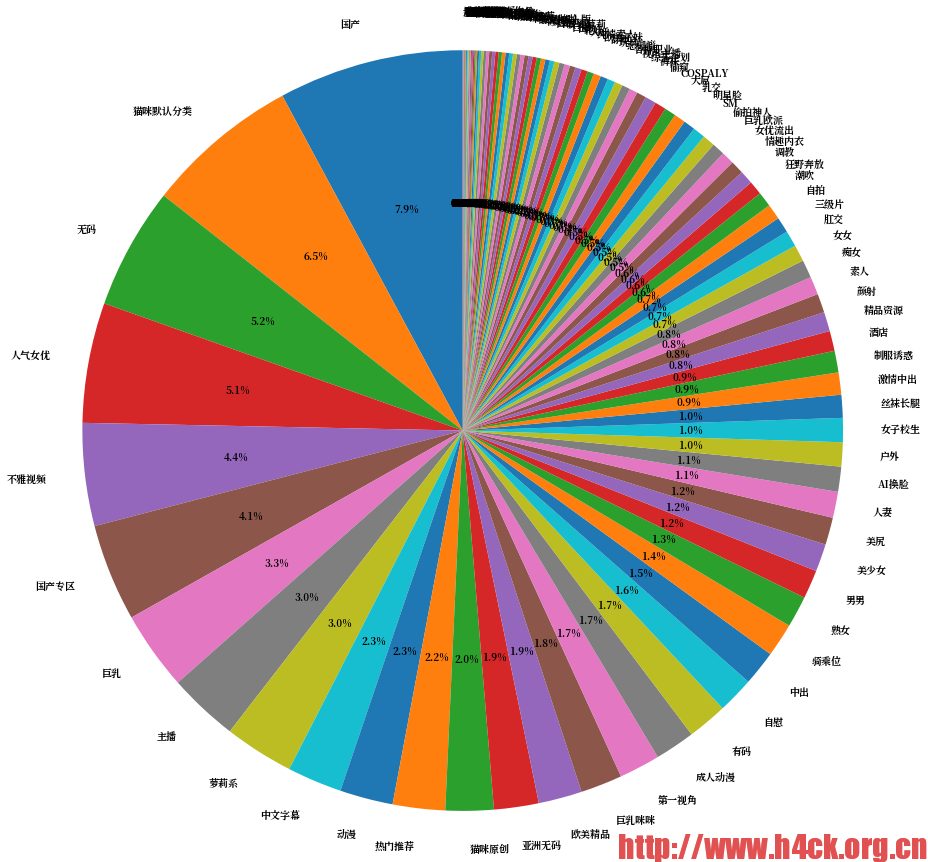
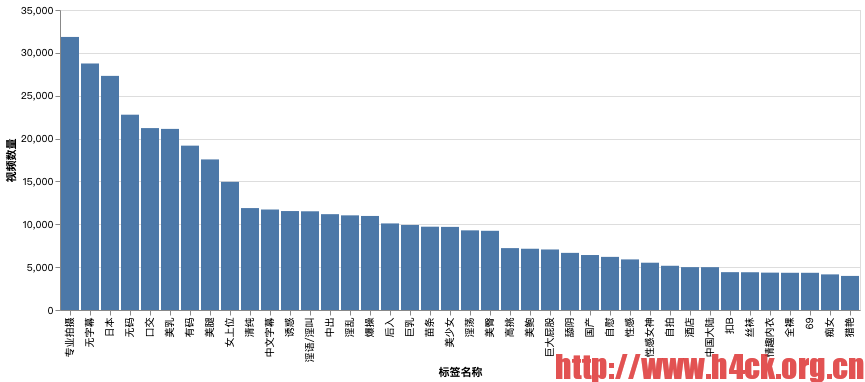
视频作者 视频分类信息分析
http://www.h4ck.org.cn
by obaby
obaby@mars
email:root@obaby.org.cn
date: 2020.09.04
'''
from pyspark.sql.functions import col
import altair as alt
import pandas as pd
from matplotlib import pyplot as plt
%matplotlib inline
csv = spark.read.option("header",True).csv("hdfs://localhost:9000/data2/porn_data_movie.csv")
csv.printSchema()
root |-- id: string (nullable = true) |-- create: string (nullable = true) |-- update: string (nullable = true) |-- name: string (nullable = true) |-- describe: string (nullable = true) |-- source_id: string (nullable = true) |-- publish_time: string (nullable = true) |-- play_count: string (nullable = true) |-- good_count: string (nullable = true) |-- bad_count: string (nullable = true) |-- link_count: string (nullable = true) |-- comment_count: string (nullable = true) |-- designation: string (nullable = true) |-- category_id: string (nullable = true) |-- porn_site_id: string (nullable = true) |-- uploader_id: string (nullable = true) |-- producer: string (nullable = true)
csv.select('name', 'describe', 'uploader_id').show()
from pyspark.sql.functions import col
import altair as alt
import pandas as pd
from matplotlib import pyplot as plt
get_ipython().run_line_magic('matplotlib', 'inline')
csv = spark.read.option("header",True).csv("hdfs://localhost:9000/data2/porn_data_movie_tags.csv")
tag_csv = spark.read.option("header",True).csv("hdfs://localhost:9000/data2/porn_data_tag.csv")
csv.show()
+---+--------+------+ | id|movie_id|tag_id| +---+--------+------+ | 1| 9909| 1| | 2| 9909| 2| | 3| 9909| 3| | 4| 9909| 4| | 5| 9910| 5| | 6| 9910| 6| | 7| 9910| 7| | 8| 9910| 8| | 9| 9910| 9| | 10| 9910| 10| | 11| 9911| 12| | 12| 9911| 2| | 13| 9911| 1| | 14| 9911| 13| | 15| 9910| 11| | 16| 9911| 14| | 17| 9911| 15| | 18| 9911| 5| | 19| 9910| 16| | 20| 9910| 17| +---+--------+------+ only showing top 20 rows
'''
--------------------------------------------------------------------------------
福利数据解析
基础数据分析,标题分词,词频统计
-----------------------------------
by:obaby
email: root@obaby.org.cn
blog:http://www.h4ck.org.cn
===================================
参考链接:https://sparkbyexamples.com/pyspark/select-columns-from-pyspark-dataframe/
-------------------------------------------------------------------------------
'''
import jieba
# 通过spark read csv格式文件,从csv header解析数据结构
csv = spark.read.option("header",True).csv("hdfs://localhost:9000/data2/porn_data_movie.csv")
# 数据格式
csv.printSchema()
root
|-- id: string (nullable = true)
|-- create: string (nullable = true)
|-- update: string (nullable = true)
|-- name: string (nullable = true)
|-- describe: string (nullable = true)
|-- source_id: string (nullable = true)
|-- publish_time: string (nullable = true)
|-- play_count: string (nullable = true)
|-- good_count: string (nullable = true)
|-- bad_count: string (nullable = true)
|-- link_count: string (nullable = true)
|-- comment_count: string (nullable = true)
|-- designation: string (nullable = true)
|-- category_id: string (nullable = true)
|-- porn_site_id: string (nullable = true)
|-- uploader_id: string (nullable = true)
|-- producer: string (nullable = true)