
不知道有没有和姐姐我一样把所有美女的图片都下载下来的,如果没有下载的话可以通过博客的搜索功能搜索爬虫去下载妹子图片了哦。通过爬取的乱七八糟的各种网站,目前粗略的估计所有下载的图片大约有1T左右了。由于各个网站都是分别的下载的,所有下载后的图片会有很多重复的。想找一个图片处理工具,找了半天有个什么推荐的eagle的工具,还是收费的,可以免费试用一个月。结果我把下载的图片目录加进去直接卡死了。啊哈哈。这就离谱,所以如果没有图片处理需求的还是推荐picasa3,我也有发布一个补丁工具,真的是一代神器。
既然没有现成的工具,那就写一个吧,具体的要求:
1.能够把所有文件复制到同一个目录下(这不是废话嘛,就是为了干这个的啊) 2.能够过滤10k以下的非图片文件(多数是由于被爬取网站不稳定导致的下载失败,其实不是图片文件) 3.对于不同网站下载的同一个图片不要重复复制(通过计算文件md5的方法进行规避) 4.能够记录整理日志(当然啊,不然那么多文件中间关机了,岂不是得全部再来一遍) 主要就是上面的几个要求啦~~~
话不多说,开干吧,为了简化代码,这里没有使用os模块,相对代码也就简单了很多,完整代码如下:
# 妹子图整理工具 by obaby
# http://h4ck.org.cn
# http://nai.dog
# 按 Shift+F10 执行或将其替换为您的代码。
# 按 双击 Shift 在所有地方搜索类、文件、工具窗口、操作和设置。
from pathlib import Path
import hashlib
import shutil
from pyfiglet import Figlet
source_file_paths = [
Path(r'I:\jpmvb'),
Path(r'I:\ku138'),
Path(r'I:\微图坊'),
Path(r'G:\xgmn'),
Path(r'G:\xrmnw'),
Path(r'G:\图片'),
Path(r'G:\秀人集')
]
dest_file_path = Path('I:\Beauty_Images')
def get_done_paths():
p = Path('logs.txt')
if not p.exists():
return []
with Path('logs.txt') as f:
content = open(f, 'r', encoding='utf8')
return [c.strip() for c in content.readlines()]
def append_done_paths(path_name):
p = Path('logs.txt')
content = open(p, 'a+', encoding='utf8')
content.write(path_name + '\n')
def print_hack():
print('*' * 100)
# f = Figlet(font='slant')
f = Figlet()
print(f.renderText('obaby@mars'))
print('美女图片整理工具 V1.0')
print('Verson: 23.01.09')
print('Blog: http://www.h4ck.org.cn')
print('*' * 100)
done_paths = get_done_paths()
def calc_file_md5(img):
content = open(img, 'rb').read()
file_md5 = hashlib.md5(content).hexdigest()
return file_md5
def get_image_md5_in_path(p):
md5_list = []
for img in p.glob('*.*'):
md5_list.append(calc_file_md5(img))
return md5_list
def copy_image_to_dest(p):
global done_paths
print('=' * 200)
print('[M] 开始复制目录' + p.name + ' ......')
for dir in p.iterdir():
if str(dir.resolve()) in done_paths:
print('[*]' + dir.name + ' 已经完成复制,跳过')
print('*' * 100)
continue
dest_parts = dir.parts[-1]
dest_path = dest_file_path / dest_parts
img_md5_list = []
if dest_path.exists():
print('[D] 目标文件路径:'+ dest_path.name + '已经存在,正在创建图片md5 列表')
img_md5_list = get_image_md5_in_path(dest_path)
print('[D] Md5 list = ' , img_md5_list)
else:
dest_path.mkdir(parents=True, exist_ok=False)
for img in dir.glob('*.*'):
# print(img)
# 处理大于100k文件
if int(img.stat().st_size) > 10000:
image_name = img.name
if len(img_md5_list) > 0 :
img_md5 = calc_file_md5(img)
if img_md5 in img_md5_list:
print('[*]' + img.name + ' 检测到存在同值md5文件,跳过')
continue
else:
dest_image_file_path = dest_path / image_name
shutil.copy(img, dest_image_file_path)
print('[*]' + img.name + ' 已经复制')
else:
print('[*]' + img.name + ' 文件小于10k,跳过')
print('[*]' + dir.name + ' 目录复制完成,添加到完成列表')
print('-' * 200)
append_done_paths(str(dir.resolve()))
done_paths.append(str(dir.resolve()))
# 按间距中的绿色按钮以运行脚本。
if __name__ == '__main__':
print_hack()
# append_done_paths('c/dir')
# done_list = get_done_paths()
# print(done_list)
# test_path = Path(r'G:\秀人集')
# tp = Path(r'G:\秀人集\[XINGYAN星颜社]VOL.154_女神王雨纯脱深色日式和服露性感白色内衣配超薄肉丝诱惑写真82P')
# print(tp.name)
# ml = get_image_md5_in_path(Path(r'G:\秀人集\[XINGYAN星颜社]VOL.154_女神王雨纯脱深色日式和服露性感白色内衣配超薄肉丝诱惑写真82P'))
# print(ml)
print('*' * 100)
print('[S] 开始处理图片:')
for p in source_file_paths:
copy_image_to_dest(p)
print('[D] 所有目录复制完成。请欣赏图片吧。')
print('*' * 100)
实际复制效果也挺好的,磁盘基本跑慢了:
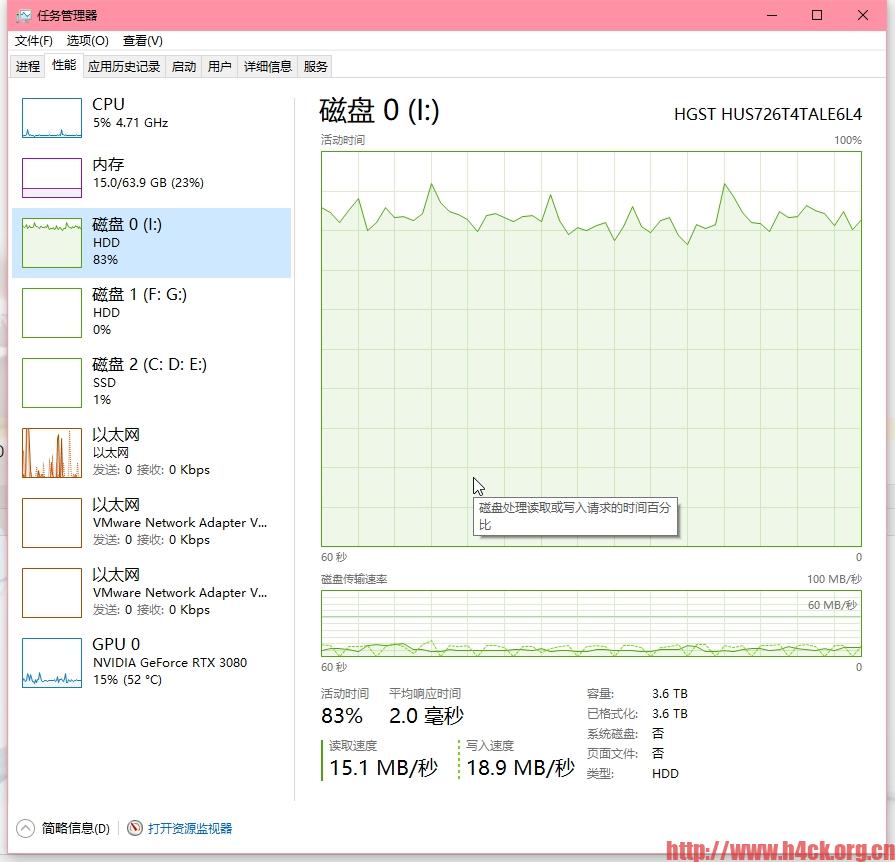
目标路径:

整理的时候修改这两个路径即可:
source_file_paths = [
Path(r'I:\jpmvb'),
Path(r'I:\ku138'),
Path(r'I:\微图坊'),
Path(r'G:\xgmn'),
Path(r'G:\xrmnw'),
Path(r'G:\图片'),
Path(r'G:\秀人集')
]
dest_file_path = Path('I:\Beauty_Images')
运行环境Python 3.8及以上,pip列表:
(venv) PS F:\Pycharm_Projects\beauty_image_copyer> pip list Package Version ---------- --------- pyfiglet 0.8.post1
11 comments
我也写了很多整理的脚本
wow,看来好东西也不少哦~~~多分享啊·~~
都是临时写的定制脚本,对别人没什么用。而且我写 PHP 代码,还要安装环境,没那么方便使用
嗯嗯,其实python的运行环境也比较麻烦。所以发的各种爬虫都是打包成exe了。
晚上都这么晚睡的嘛?精神真好呢~~
看看就好,没有收集过美女照片。
是时候开始收集图片啦~~~~
上次的爬虫还没有跑完,总是运行一会就断!
影响杜老师体验啦,非常抱歉哦。因为没有做太多的异常兼容处理,不要问为神马啦。问的话就是因为懒啊。但是可以用批处理的死循环来解决异常退出的问题啊,可以参考下面的代码(以精品美女吧为例):
chcp 65001
echo "Start spider"
title jpmnb spider
echo off
:loop
F:\Pycharm_Projects\sexy_girl_spider\dist\jpmnb\jpmnb.exe -a -r -e -s https://www.jpmnb.net
goto :loop
-e 参数是控制提前停止爬取分类的,如果要全站爬取去掉这个参数就ok啦。
推荐个图片管理观看软件 digiKam ,初次处理的时候比较慢,但是看图很方便,就是网络集合有点麻烦,好像有种网盘本地的玩法,没具体研究过,大部分都是把资源放在nas上。
这个没用过,试过几个所谓的看图工具,效果都非常差,对于我差不多1t的图片资源直接加载的时候就完蛋了。更不用说去查看了,目前还是使用google的picasa3.